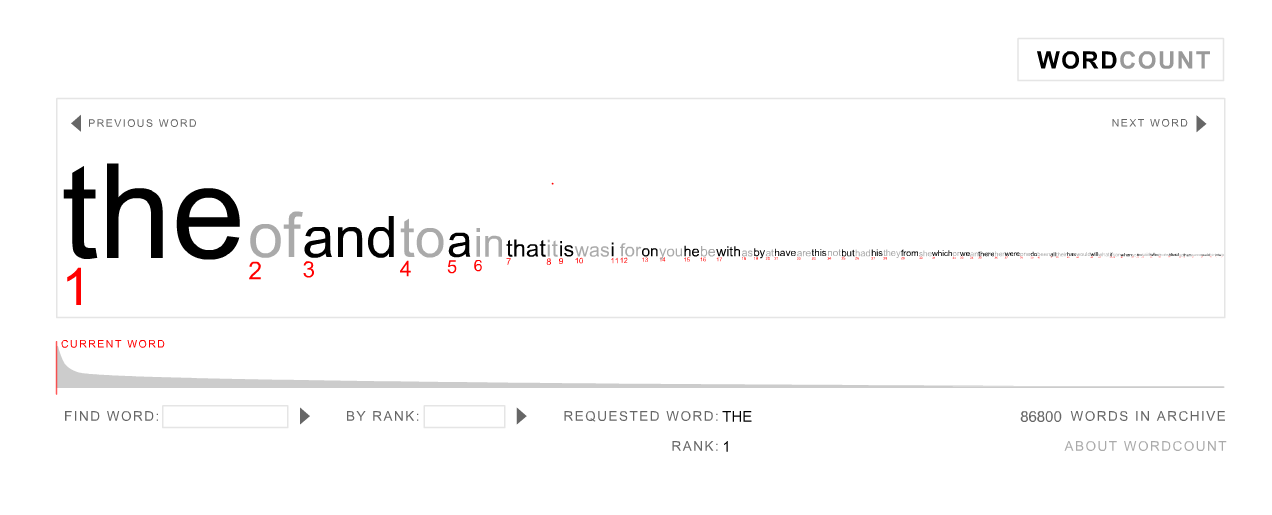
In a recent post I explained that in a large database of containing the words from many English language texts of various types, the word ‘football’ occurred 25,271 times, making it the 1543rd most common word in the database. I also said that the word ‘baseball’ occurred 28,851 times, and asked you to guess what its rank would be.
With just this information available, it’s impossible to say with certainty what the exact rank will be. We know that ‘baseball’ is more frequent than ‘football’ and so it must have a higher rank (which means a rank with a lower number). But that simply means it could be anywhere from 1 to 1542.
However, we’d probably guess that ‘baseball’ is not so much more popular a word than ‘football’; certainly other words like ‘you’, ‘me’, ‘please’ and so on are likely to occur much more frequently. So, we might reasonably guess that the rank of ‘baseball’ is closer to the lower limit of 1542 than it is to the upper limit of 1. But where exactly should we place it?
Zipf’s law provides a possible answer.
In its simplest form Zipf’s law states that for many types of naturally occurring data – including frequencies of word counts – the second most common word occurs half as often as the most common; the third most common occurs a third as often as the most popular; the fourth most common occurs a quarter as often; and so on. If we denote by f(r) the frequency of the item with rank r, this means that
f(r) = C/r
or
r\times f(r)=C,
where C is the constant f(1). And since this is true for every choice of r, the frequencies and ranks of the words ranked r and s are related by
r\times f(r)=s \times f(s).
Then, assuming Zipf’s law applies,
rank(\text{`baseball'}) = rank(`football') \times f(\text{`football'})/f(\text{`baseball'})
= 1543 \times 25271/28851 \approx 1352
So, how accurate is this estimate? The database I extracted the data from is the well-known Brown University Standard Corpus of Present-Day American English. The most common 5000 words in the database, together with their frequencies, can be found here. Searching down the list, you’ll find that the rank of ‘baseball’ is 1380, so the estimated value of 1352 is not that far out.
But where does Zipf’s law come from? It’s named after the linguist George Kingsley Zipf (1902-1950), who observed the law to hold empirically for words in different languages. Rather like Benford’s law, which we discussed in an earlier post, different arguments can be constructed that suggest Zipf’s law might be appropriate in certain contexts, but none is overwhelmingly convincing, and it’s really the body of empirical evidence that provides its strongest support.
Actually, Zipf’s law
f(r) = C/r,
is equivalent to saying that the frequency distribution follows a power law where the power is equal to -1. But many fits of the model to data can be improved by generalising this model to
f(r)=C/r^k
for some constant k. In this more general form the law has been shown to work well in many different contexts, including sizes of cities, website access counts, gene expression frequencies and strength of volcanic eruptions. The version with k=1 is found to work well for many datasets based on frequencies of word counts, but other datasets often require different values of k. But to use this more general version of the law we’d have to know the value of k, which we could estimate if we had sufficient amounts of data. The simpler Zipf’s law has k=1 implicitly, and so we were able to estimate the rank of ‘baseball’ with just the limited amount of information provided.
Finally, I had just 3 responses to the request for predictions of the rank of ‘baseball’: 1200, 1300 and 1450, each of which is entirely plausible. But if I regard each of these estimates as those of an expert and try combining those expert opinions by taking the average I get 1317, which is very close to the Zipf law prediction of 1352. Maybe if I’d had more replies the average would have been even closer to the Zipf law estimate or indeed to the true answer itself 😏.
